"All the Deep-Learning DevOps your research needs, and then some... Because ain't nobody got time for that"




Trains Agent is an AI experiment cluster solution.
It is a zero configuration fire-and-forget execution agent, which combined with trains-server provides a full AI cluster solution.
Full AutoML in 5 steps
pip install trains-agent (install the Trains Agent on any GPU machine: on-premises / cloud / ...)Using the Trains Agent, you can now set up a dynamic cluster with *epsilon DevOps
*epsilon - Because we are scientists :triangular_ruler: and nothing is really zero work
(Experience Trains live at https://demoapp.trains.allegro.ai)
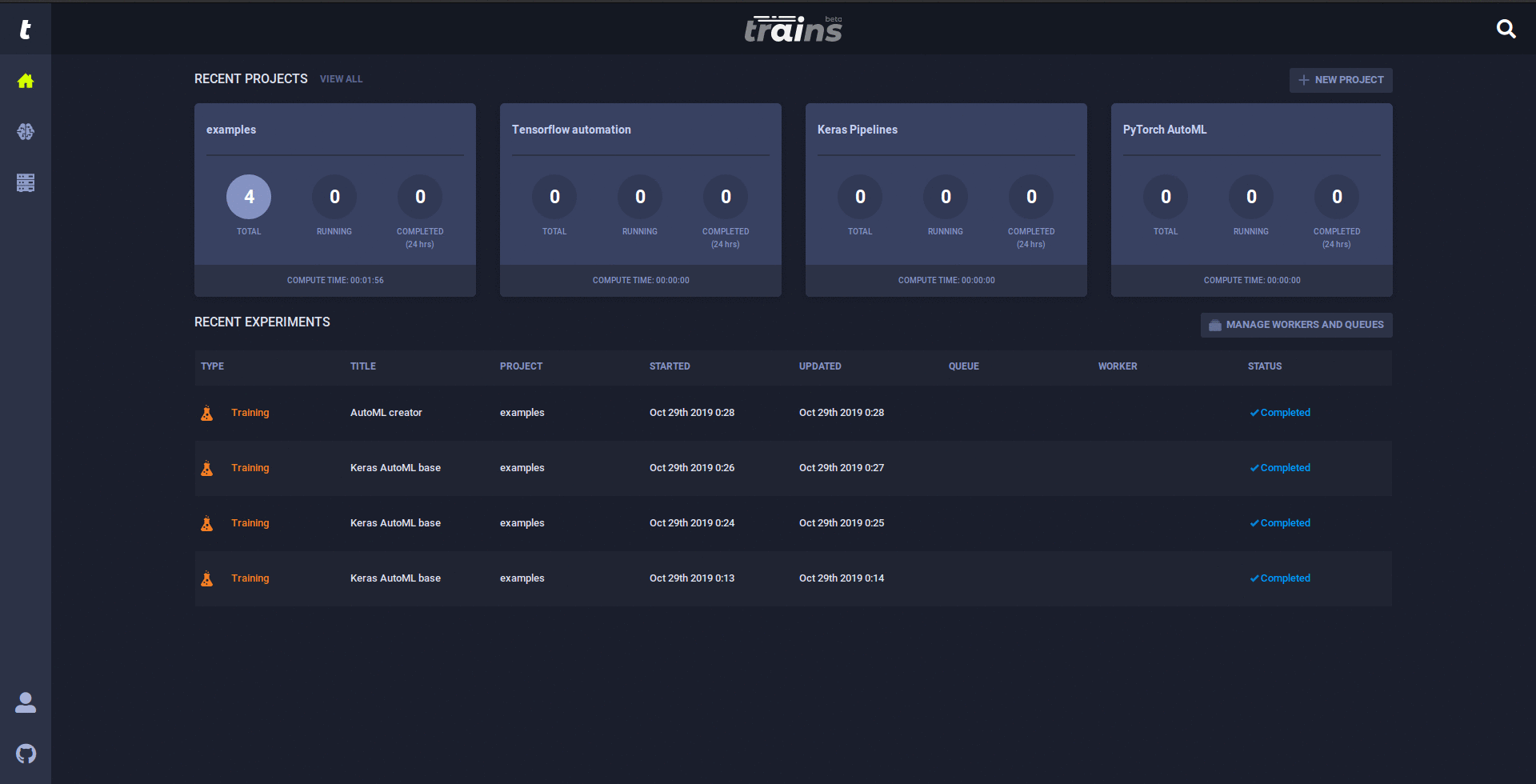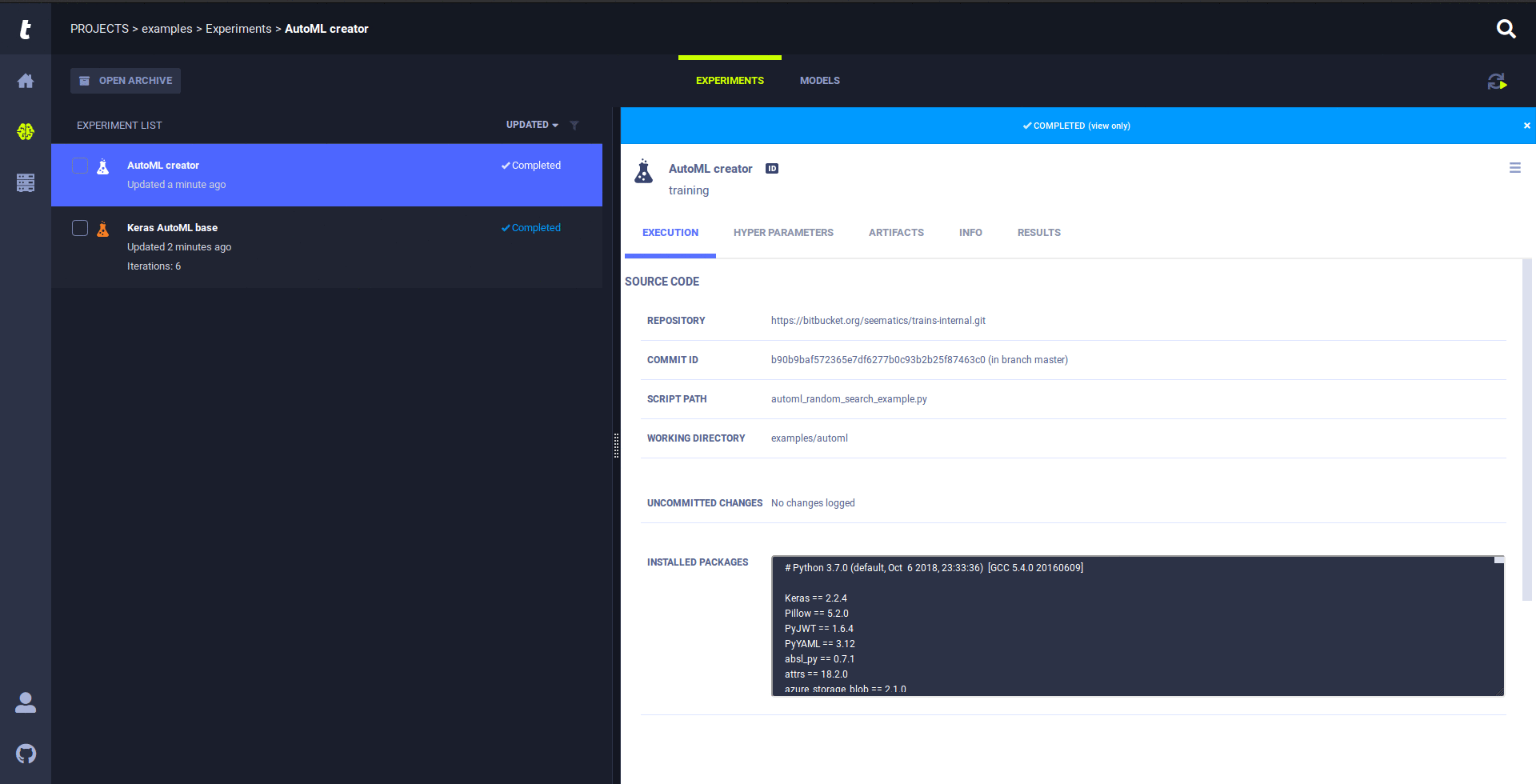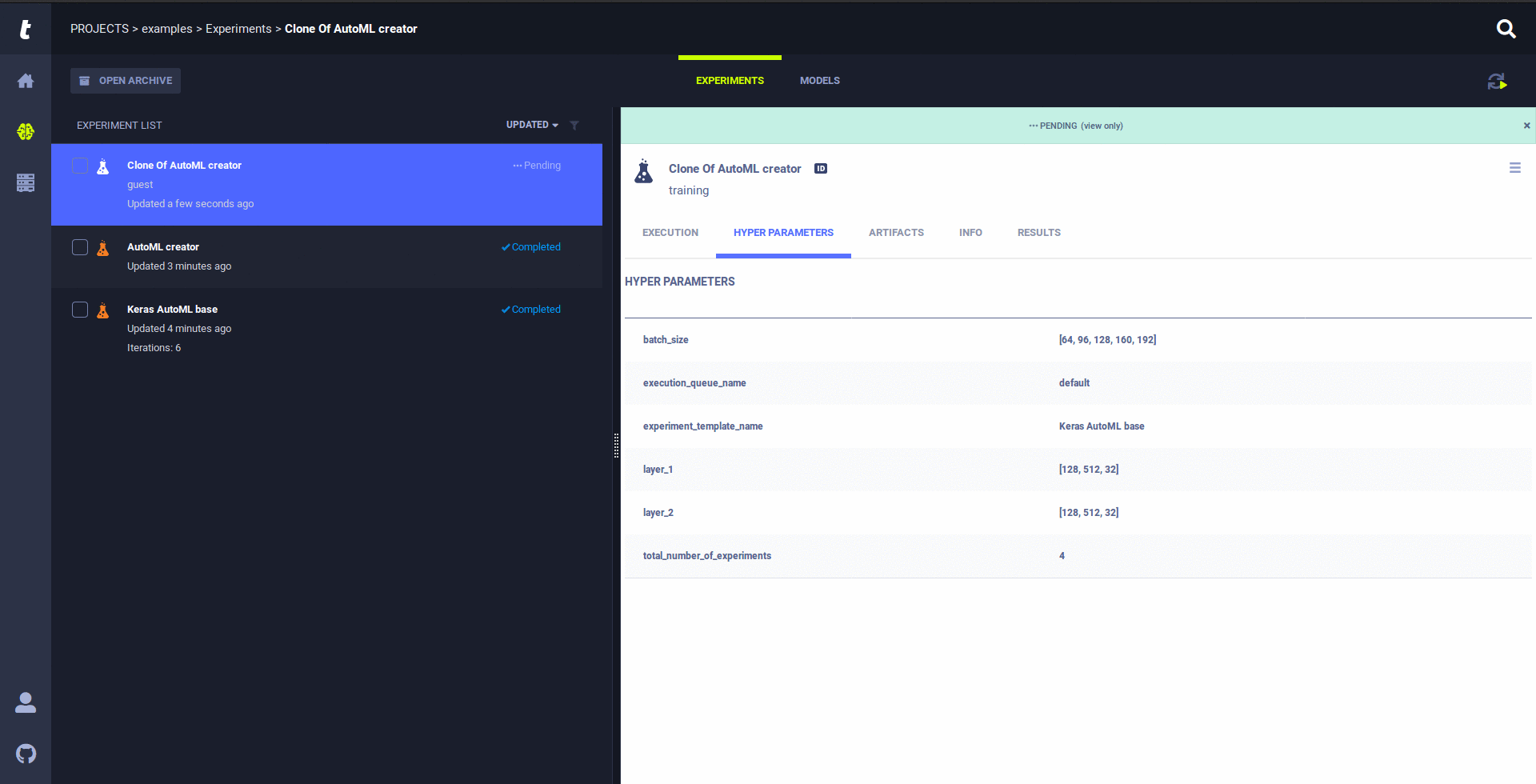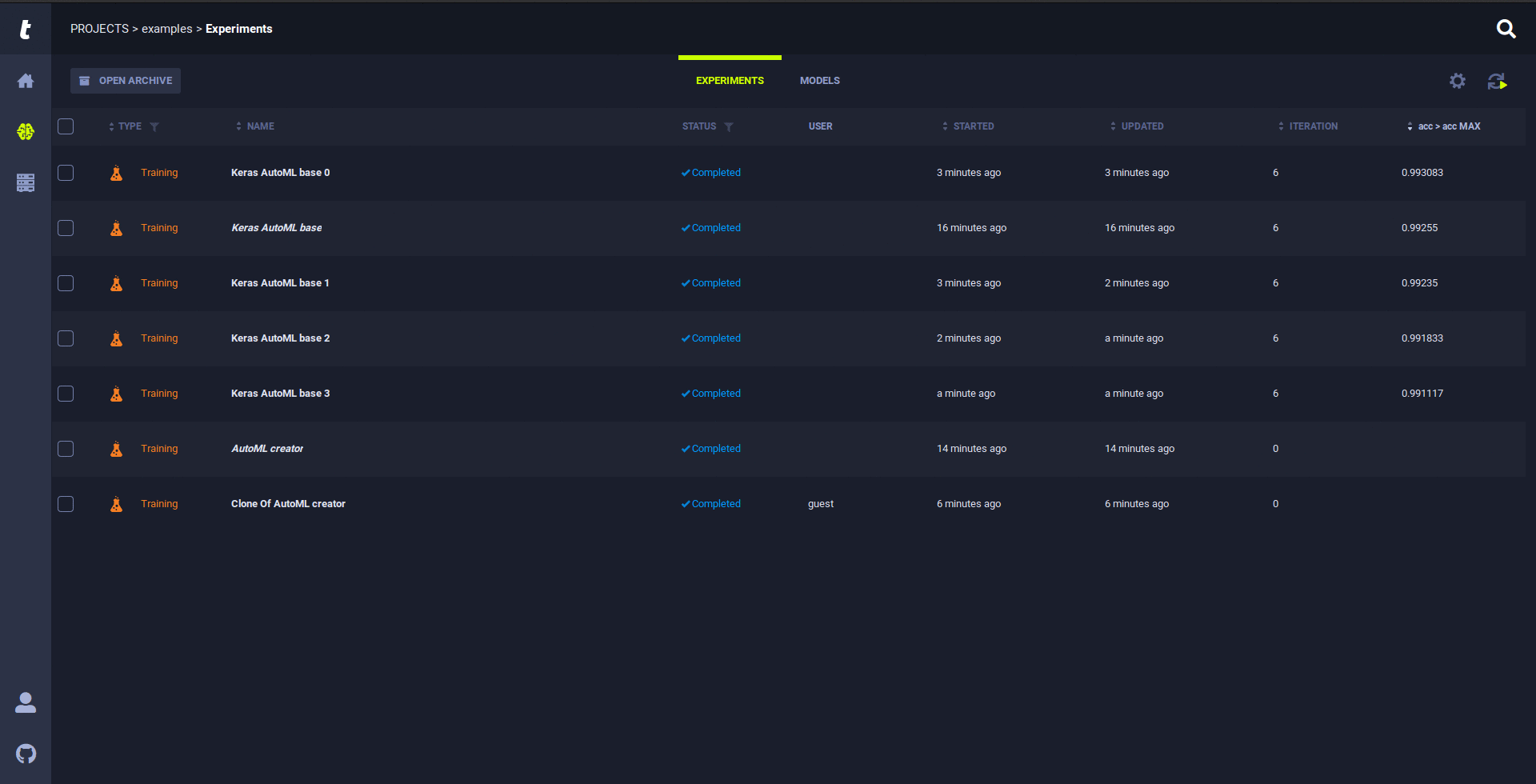
The Trains Agent was built to address the DL/ML R&D DevOps needs:
We think Kubernetes is awesome.
Combined with KubeFlow it is a robust solution for production-grade DevOps.
We've observed, however, that it can be a bit of an overkill as an R&D DL/ML solution.
If you are considering K8S for your research, also consider that you will soon be managing hundreds of containers...
In our experience, handling and building the environments, having to package every experiment in a docker, managing those hundreds (or more) containers and building pipelines on top of it all, is very complicated (also, it’s usually out of scope for the research team, and overwhelming even for the DevOps team).
We feel there has to be a better way, that can be just as powerful for R&D and at the same time allow integration with K8S when the need arises.
(If you already have a K8S cluster for AI, detailed instructions on how to integrate Trains into your K8S cluster are here with included helm chart)
Full scale HPC with a click of a button
The Trains Agent is a job scheduler that listens on job queue(s), pulls jobs, sets the job environments, executes the job and monitors its progress.
Any 'Draft' experiment can be scheduled for execution by a Trains agent.
A previously run experiment can be put into 'Draft' state by either of two methods:
An experiment is scheduled for execution using the 'Enqueue' action from the experiment right-click context menu in the Trains UI and selecting the execution queue.
See creating an experiment and enqueuing it for execution.
Once an experiment is enqueued, it will be picked up and executed by a Trains agent monitoring this queue.
The Trains UI Workers & Queues page provides ongoing execution information:
The Trains Agent executes experiments using the following process:
+-----------------+
| GPU Machine |
Development Machine | |
+------------------------+ | +-------------+ |
| Data Scientist's | +--------------+ | |Trains Agent | |
| DL/ML Code | | WEB UI | | | | |
| | | | | | +---------+ | |
| | | | | | | DL/ML | | |
| | +--------------+ | | | Code | | |
| | User Clones Exp #1 / . . . . . . . / | | | | | |
| +-------------------+ | into Exp #2 / . . . . . . . / | | +---------+ | |
| | Trains | | +---------------/-_____________-/ | | | |
| +---------+---------+ | | | | ^ | |
+-----------|------------+ | | +------|------+ |
| | +--------|--------+
Auto-Magically | |
Creates Exp #1 | The Trains Agent
\ User Change Hyper-Parameters Pulls Exp #2, setup the
| | environment & clone code.
| | Start execution with the
+------------|------------+ | +--------------------+ new set of Hyper-Parameters.
| +---------v---------+ | | | Trains Server | |
| | Experiment #1 | | | | | |
| +-------------------+ | | | Execution Queue | |
| || | | | | |
| +-------------------+<----------+ | | |
| | | | | | |
| | Experiment #2 | | | | |
| +-------------------<------------\ | | |
| | ------------->---------------+ | |
| | User Send Exp #2 | |Execute Exp #2 +--------------------+
| | For Execution | +---------------+ |
| Trains Server | | |
+-------------------------+ +--------------------+pip install trains-agentFull Interface and capabilities are available with
trains-agent --help
trains-agent daemon --helptrains-agent initNote: The Trains Agent uses a cache folder to cache pip packages, apt packages and cloned repositories. The default Trains Agent cache folder is ~/.trains
See full details in your configuration file at ~/trains.conf
Note: The Trains agent extends the Trains configuration file ~/trains.conf
They are designed to share the same configuration file, see example here
For debug and experimentation, start the Trains agent in foreground mode, where all the output is printed to screen
trains-agent daemon --queue default --foregroundFor actual service mode, all the stdout will be stored automatically into a temporary file (no need to pipe)
Notice: with --detached flag, the trains-agent will be running in the background
trains-agent daemon --detached --queue defaultGPU allocation is controlled via the standard OS environment NVIDIA_VISIBLE_DEVICES or --gpus flag (or disabled with --cpu-only).
If no flag is set, and NVIDIA_VISIBLE_DEVICES variable doesn't exist, all GPU's will be allocated for the trains-agent
If --cpu-only flag is set, or NVIDIA_VISIBLE_DEVICES is an empty string (""), no gpu will be allocated for the trains-agent
Example: spin two agents, one per gpu on the same machine:
Notice: with --detached flag, the trains-agent will be running in the background
trains-agent daemon --detached --gpus 0 --queue default
trains-agent daemon --detached --gpus 1 --queue defaultExample: spin two agents, pulling from dedicated dual_gpu queue, two gpu's per agent
trains-agent daemon --detached --gpus 0,1 --queue dual_gpu
trains-agent daemon --detached --gpus 2,3 --queue dual_gpuFor debug and experimentation, start the Trains agent in foreground mode, where all the output is printed to screen
trains-agent daemon --queue default --docker --foregroundFor actual service mode, all the stdout will be stored automatically into a file (no need to pipe)
Notice: with --detached flag, the trains-agent will be running in the background
trains-agent daemon --detached --queue default --dockerExample: spin two agents, one per gpu on the same machine, with default nvidia/cuda docker:
trains-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda
trains-agent daemon --detached --gpus 1 --queue default --docker nvidia/cudaExample: spin two agents, pulling from dedicated dual_gpu queue, two gpu's per agent, with default nvidia/cuda docker:
trains-agent daemon --detached --gpus 0,1 --queue dual_gpu --docker nvidia/cuda
trains-agent daemon --detached --gpus 2,3 --queue dual_gpu --docker nvidia/cudaPriority Queues are also supported, example use case:
High priority queue: important_jobs Low priority queue: default
trains-agent daemon --queue important_jobs defaultThe Trains Agent will first try to pull jobs from the important_jobs queue, only then it will fetch a job from the default queue.
Adding queues, managing job order within a queue and moving jobs between queues, is available using the Web UI, see example on our open server
Integrate Trains with your code
Execute the code on your machine (Manually / PyCharm / Jupyter Notebook)
As your code is running, Trains creates an experiment logging all the necessary execution information:
You now have a 'template' of your experiment with everything required for automated execution
In the Trains UI, Right click on the experiment and select 'clone'. A copy of your experiment will be created.
You now have a new draft experiment cloned from your original experiment, feel free to edit it
Schedule the newly created experiment for execution: Right-click the experiment and select 'enqueue'
Trains-Agent Services is a special mode of Trains-Agent that provides the ability to launch long-lasting jobs that previously had to be executed on local / dedicated machines. It allows a single agent to launch multiple dockers (Tasks) for different use cases. To name a few use cases, auto-scaler service (spinning instances when the need arises and the budget allows), Controllers (Implementing pipelines and more sophisticated DevOps logic), Optimizer (such as Hyper-parameter Optimization or sweeping), and Application (such as interactive Bokeh apps for increased data transparency)
Trains-Agent Services mode will spin any task enqueued into the specified queue. Every task launched by Trains-Agent Services will be registered as a new node in the system, providing tracking and transparency capabilities. Currently trains-agent in services-mode supports cpu only configuration. Trains-agent services mode can be launched alongside GPU agents.
trains-agent daemon --services-mode --detached --queue services --create-queue --docker ubuntu:18.04 --cpu-onlyNote: It is the user's responsibility to make sure the proper tasks are pushed into the specified queue.
The Trains Agent can also be used to implement AutoML orchestration and Experiment Pipelines in conjunction with the Trains package.
Sample AutoML & Orchestration examples can be found in the Trains example/automl folder.
AutoML examples
Experiment Pipeline examples
Apache License, Version 2.0 (see the LICENSE for more information)