 [](https://lgtm.com/projects/g/medipixel/rl_algorithms/context:python)
[](https://opensource.org/licenses/MIT)
[](https://github.com/psf/black)
[](#contributors-)
[](https://lgtm.com/projects/g/medipixel/rl_algorithms/context:python)
[](https://opensource.org/licenses/MIT)
[](https://github.com/psf/black)
[](#contributors-)
This repository contains Reinforcement Learning algorithms which are being used for research activities at Medipixel. The source code will be frequently updated. We are warmly welcoming external contributors! :)
 |
 |
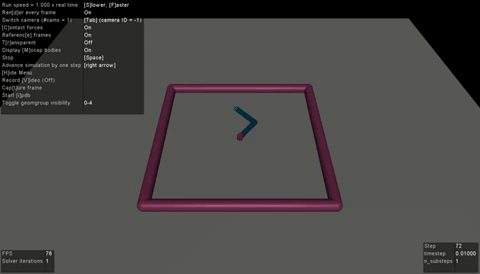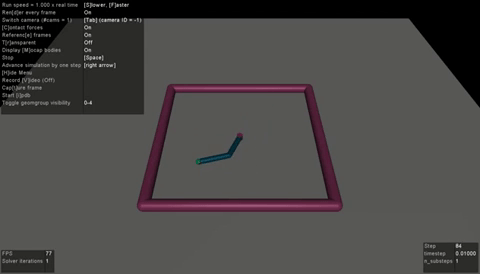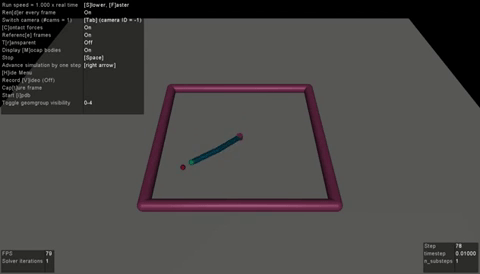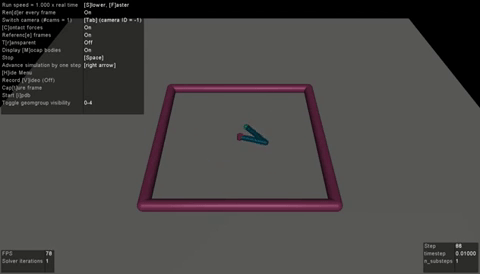 |
|---|---|---|
| BC agent on LunarLanderContinuous-v2 | RainbowIQN agent on PongNoFrameskip-v4 | SAC agent on Reacher-v2 |
Thanks goes to these wonderful people (emoji key):
 Jinwoo Park (Curt) 💻 |
 Kyunghwan Kim 💻 |
 darthegg 💻 |
 Mincheol Kim 💻 |
 김민섭 💻 |
 Leejin Jung 💻 |
 Chris Yoon 💻 |
This project follows the all-contributors specification.
We have tested each algorithm on some of the following environments.
❗Please note that this won't be frequently updated.
RainbowIQN learns the game incredibly fast! It accomplishes the perfect score (21) within 100 episodes! The idea of RainbowIQN is roughly suggested from W. Dabney et al..
See W&B Log for more details. (The performance is measured on the commit 4248057)

RainbowIQN with ResNet's performance and learning speed were similar to those of RainbowIQN. Also we confirmed that R2D1 (w/ Dueling, PER) converges well in the Pong enviornment, though not as fast as RainbowIQN (in terms of update step).
Although we were only able to test Ape-X DQN (w/ Dueling) with 4 workers due to limitations to computing power, we observed a significant speed-up in carrying out update steps (with batch size 512). Ape-X DQN learns Pong game in about 2 hours, compared to 4 hours for serial Dueling DQN.
See W&B Log for more details. (The performance is measured on the commit 9e897ad)


We used these environments just for a quick verification of each algorithm, so some of experiments may not show the best performance.
See W&B log for more details. (The performance is measured on the commit 9e897ad)

See W&B log for more details. (The performance is measured on the commit 9e897ad)

See W&B log for more details. (The performance is measured on the commit 9e897ad)

See W&B log for more details. (The performance is measured on the commit 9e897ad)

We reproduced the performance of DDPG, TD3, and SAC on Reacher-v2 (Mujoco). They reach the score around -3.5 to -4.5.
See [W&B Log](https://app.wandb.ai/medipixel_rl/reacher-v2/reports?view=curt-park%2FBaselines%20%23158) for more details.

$ conda create -n rl_algorithms python=3.6.9
$ conda activate rl_algorithmsReacher-v2), you need to acquire Mujoco license.First, clone the repository.
git clone https://github.com/medipixel/rl_algorithms.git
cd rl_algorithmsInstall packages required to execute the code. It includes python setup.py install. Just type:
make depIf you want to modify code you should configure formatting and linting settings. It automatically runs formatting and linting when you commit the code. Contrary to make dep command, it includes python setup.py develop. Just type:
make devAfter having done make dev, you can validate the code by the following commands.
make format # for formatting
make test # for lintingYou can train or test algorithm on env_name if configs/env_name/algorithm.py exists. (configs/env_name/algorithm.py contains hyper-parameters)
python run_env_name.py --cfg-path <config-path>e.g. running soft actor-critic on LunarLanderContinuous-v2.
python run_lunarlander_continuous_v2.py --cfg-path ./configs/lunarlander_continuous_v2/sac.py <other-options>e.g. running a custom agent, if you have written your own configs: configs/env_name/ddpg-custom.py.
python run_env_name.py --cfg-path ./configs/lunarlander_continuous_v2/ddpg-custom.pyYou will see the agent run with hyper parameter and model settings you configured.
In addition, there are various argument settings for running algorithms. If you check the options to run file you should command
python <run-file> -h--test
--off-render
--log
--seed <int>
--save-period <int>
--max-episode-steps <int>
--episode-num <int>
--render-after <int>
--load-from <save-file-path>
--max-episode-steps <int>
--off-worker-render
--off-logger-render
--worker-verbose
You can show a feature map that the trained agent extract using Grad-CAM(Gradient-weighted Class Activation Mapping). Grad-CAM is a way of combining feature maps using the gradient signal, and produce a coarse localization map of the important regions in the image. You can use it by adding Grad-CAM config and --grad-cam flag when you run. For example:
python run_env_name.py --cfg-path <config-path> --test --grad-camIt can be only used the agent that uses convolutional layers like DQN for Pong environment. You can see feature maps of all the configured convolution layers.

We use W&B for logging of network parameters and others. For logging, please follow the steps below after requirement installation:
- Create a wandb account
- Check your API key in settings, and login wandb on your terminal:
$ wandb login API_KEY- Initialize wandb:
$ wandb init
For more details, read W&B tutorial.
Class diagram at #135.
❗This won't be frequently updated.
