![]()
![]()
In recent years, we have witnessed many impressive progresses of reinforcement learning (RL) including AlphaGo, OpenAI Five, etc. As for real-world applications, we have successfully applied RL to many E-commerce scenarios like session-based learning to rank, multi-turn conversational agent, etc. Compared with the supervised learning paradigm, the interactive nature of RL raises the bar of its application, as the practitioners have to
This repo provides the implementations of many widely-adopted RL algorithms (DQN, PPO, ES, etc.) in both standalone and distributed modes, so that the practitioners are enabled to apply these algorithms with the least effort. We have carefully designed and iteratively refactored our interfaces, offering our users for customizing their own RL algorithms in convenience. In the following, we first present a "quick start" example. Then we describe the features of this repo in detail and empirically evaluate EasyRL.
EasyRL can be easily installed by:
git clone https://github.com/alibaba/EasyRL.git && cd EasyRL
pip install -e . --verboseWe have provided many well-tuned examples (see demo/). For instance, users can play Pong with DQN by
python demo/run_dqn_on_pong.pywhere we have carefully tuned the hyper-parameters, so that this game Pong is expected to be solved within around 60 minutes (depending on your hardware situations).

It is convenient for users to try other hyper-parameters by modifying the MODEL_CONFIG dict, AGENT_CONFIG dict, or even the MyDQNModel class by themselves.
Here is a more comprehensive document (currently, there is a theme-related issue, we shall fix it ASAP).
We implemented EasyRL purely based on TF. Both the computation and the communication (once in a distributed mode) are expressed via the TensorFlow computation graph. Distinguished from most existing RL packages that have utilized MPI, Ray, or NCCL, EasyRL can be easily studied, integrated into your application, or migrated among various platforms.
In addition, we provide RL-oriented summary functionalities. Specifically, users are allowed to summarize any TF op in interests by simply specifying in a config file, without caring about how to coordinate the different summary ops with the different ops to be session.run, say that users are saved from overriding summary hooks.
The interactive nature of RL poses a stong need and motivation of rolling out a large number of trajectories in parallel. A straightforward idea is to replicate the agent as many actors where each interacts with its corresponding environment(s) simultaneously. On the other hand, one or more learners are desgined to update model parameters w.r.t. the collected trajectories. This idea is first formularized as Gorilla [Nair et al., 2015] and extended into variations like ApeX [Horgan et al., 2018] and Impala [Espeholt et al., 2018].
The actor-learner architecture of EasyRL is designed as the following figure presents:
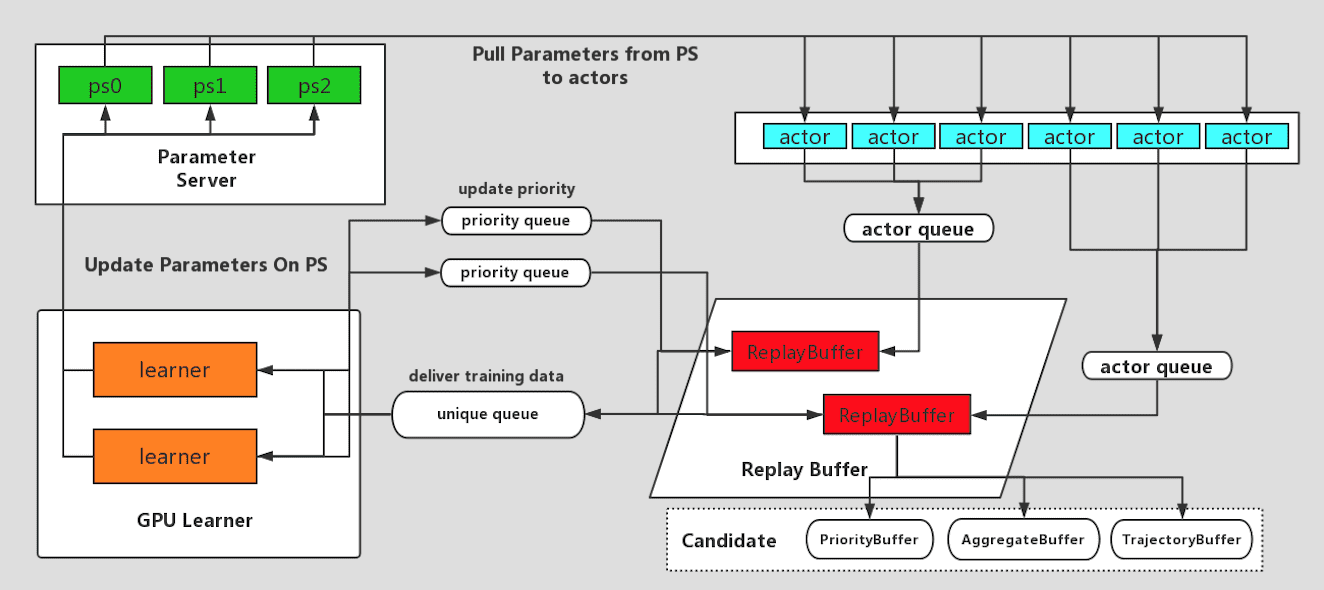 Conceptually, we categorize involved processes into four roles:
Conceptually, we categorize involved processes into four roles:
EasyRL not only provides a configurable, callable, and reliable RL algorithm suites, but also encourages users to develop their customized algorithms upon our interfaces. The whole module mainly consists of three parts: the agent classes (see easy_rl/agents), the model classes (see easy_rl/models), and the utilities (see easy_rl/utils). The agent classes expose the methods for acting, updating and communication. The model classes construct the computation graph to provide required TF placeholders and TF ops according to which kind of agent they are plugged in.
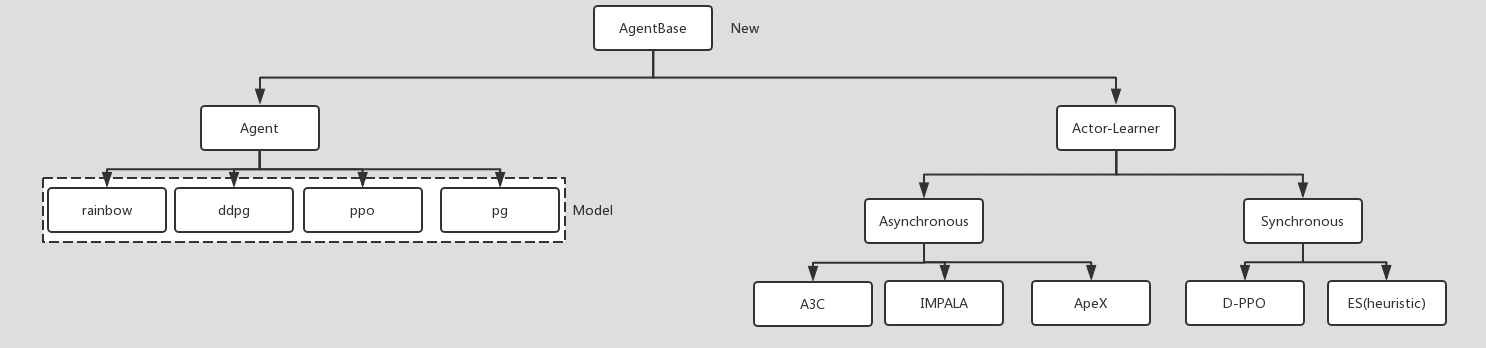
Existing agent classes are organized as follow. No matter what kind of model is adopted, Agent provide unified interfaces for runing RL algorithms in a standalone mode. As for distributed setting, ActorLearner defines the roles; SyncAgent and AsyncAgent specialize the sync/async features; and their subclasses further specialize concrete algorithms.
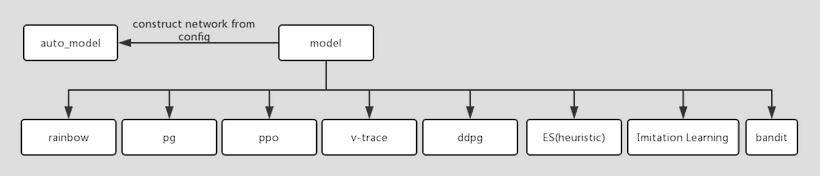
Existing model classes are organized as follow. We loosely defines the behaviors of any subclass via the base class Model. Meanwhile, we have implemented many widely-adopted models. Users are encouraged to inherit the Model class and override some of its methods, so that they can use another kind of network structure, loss function, or even the optimization algorithm.
EasyRL provides many popular RL algorithms (in both standalone and distributed setting). The following table gives a comparison between EasyRL and some impactful RL packages where o stands for existence of the corresponding functionality while x means no such one.
| Package | Rainbow | DDPG | PPO | ApeX | IMPALA | IL | ES | multi-learner | Total |
|---|---|---|---|---|---|---|---|---|---|
| EasyRL | o | o | o | o | o | o | o | o | 8 |
| Dopamine | o | x | x | x | x | x | x | x | 1 |
| Ray RLLib | o | o | o | o | o | o | o | x | 7 |
| Baseline | o | o | o | x | x | o | x | x | 4 |
| Trfl | x | x | x | x | x | x | x | x | 0 |
| Coach | 0 | 0 | 0 | x | x | 0 | x | 0 | 5 |
| TensorForce | x | o | o | x | x | x | x | o | 3 |
| RLGraph | x | o | o | x | x | x | o | x | 3 |
| Surreal | x | o | o | o | x | x | x | o | 4 |
| Uber-research/ape-x | x | x | x | o | x | x | x | x | 1 |
| PARL | x | o | o | x | o | x | o | o | 5 |
| TensorFlow Agent | x | o | o | x | x | o | x | x | 3 |
We empirically evaluate the performance of EasyRL. Our experiment focuses on the throughput and the convergence rate of our Impala and ApeX implementations. We consider Pong as our environment and preprocesses each observation into an array with shape (42, 42, 4).
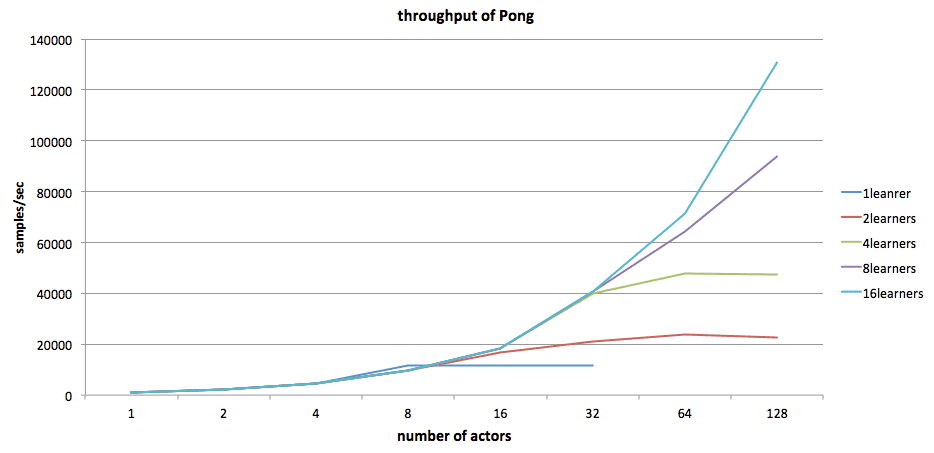
First, we study, how the throughput changes along the number of actors increases. As you can see from the following figure, once there are sufficient learners to consume the training samples without blocking the actors (i.e., the blue line corresponding to 16 learners), the throughput is almost linearly proportional to the number of actors.
Then we look into the convergence rate which is particularly critical for distributed RL, as a high throughput may not ensure solving a problem quickly if the generated samples cannot be effectively exploited. The following figure surprisingly shows that with a 4-learner, 4-buffer, 32-actor setting (yellow line), our implementation can solve Pong within 3 minutes.
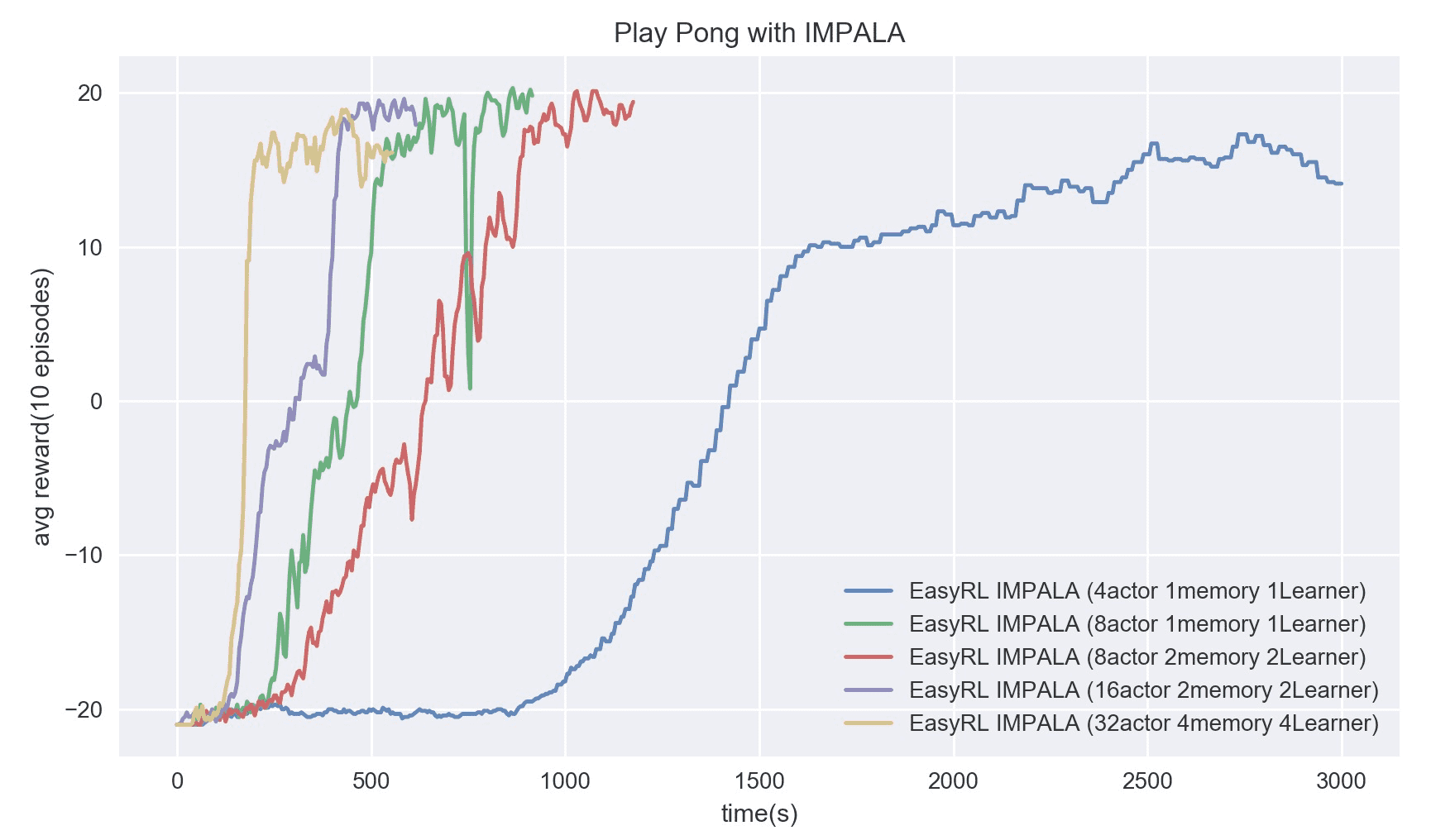 We also present the wallclock time needed to reach 17+ scores for each setting.
We also present the wallclock time needed to reach 17+ scores for each setting.
| Setting | 4a1m1 | 8a2m2l | 8a1m1 | 16a2m2l | 32a4m4l |
|---|---|---|---|---|---|
| Cost (sec.) | 1940 | 765 | 525 | 400 | 160 |
From Ray RLLib's results, we see that, with two Nvidia V100 and 32 actors, they used around 360~420 seconds to reach above 17+ scores, which is outperformed by our 32a4m4l setting and comparable with our 16a2m2l setting.
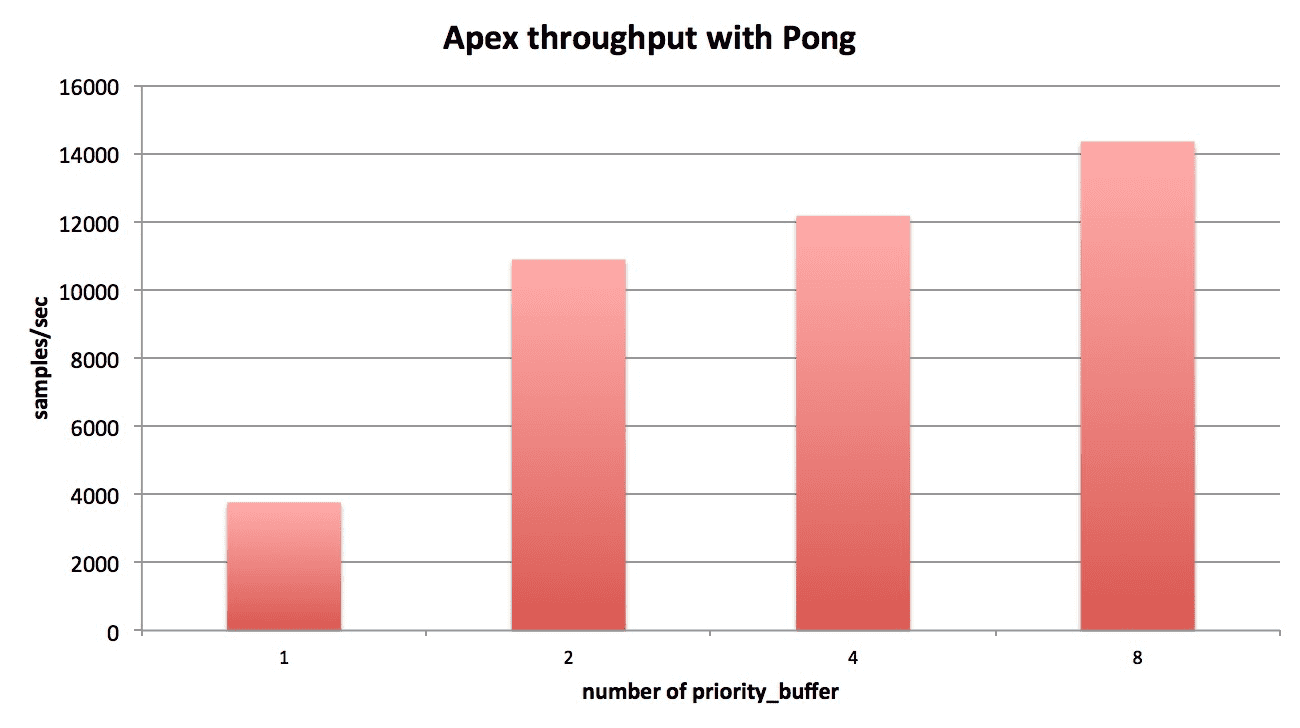
We carefully analyzed the relationships between the throughput of ApeX and the numbers of actor, memory, and learner processes. As an off-policy algorithm with replay buffers, the bottleneck is either the memory or the learner. As the following figure shows, once we had more than 2 memory processes, the only learner process becomes the bottleneck.
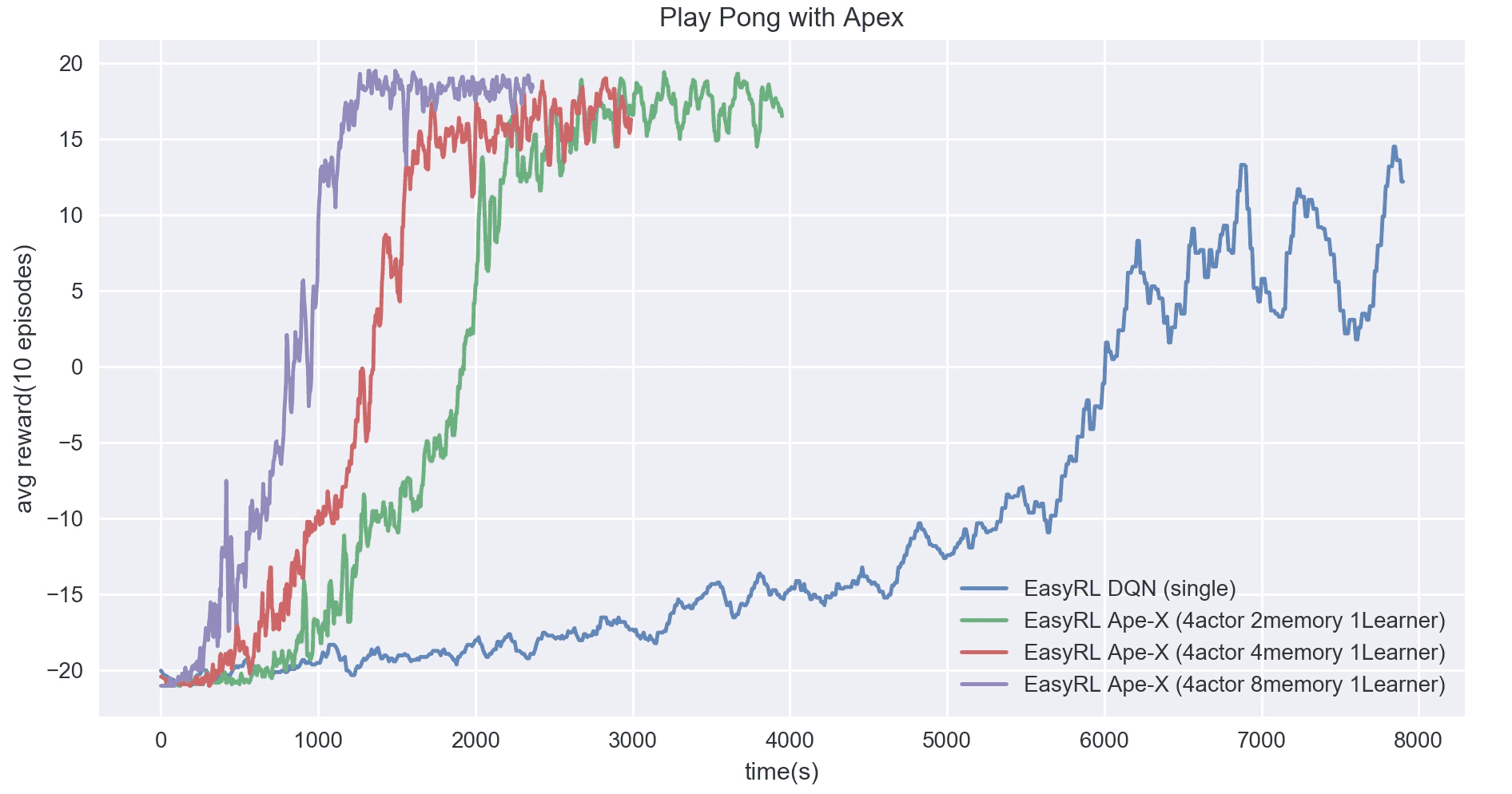
We also observed the changes in convergence rate against different number of memory processes. Even though increasing the number of memory processes cannot increase the throughput drastically, the 4a8m1l setting outperforms others by a considerable margin. When compared with Ray RLLib's results which uses 32 actors to reach 17+ scores until around 3600 seconds, our 4a8m1l setting surprisingly reduces around half of the time.
In a word, our design of actor-learner architecture is expressive for both on-policy and off-policy algorithms and enables us to easily develop some popular RL algorithms with comparable or better performance w.r.t. the SOTA RL packages.
References