
![]()
PalDB is an embeddable write-once key-value store written in Java.
PalDB is an embeddable persistent key-value store with very fast read performance and compact store size. PalDB stores are single binary files written once and ready to be used in applications.
PalDB's JAR is only 110K and has a single dependency (snappy, which isn't mandatory). It's also very easy to use with just a few configuration parameters.
Because PalDB is read-only and only focuses on data which can be held in memory it is significantly less complex than other embeddable key-value stores and therefore allows a compact storage format and very high throughput. PalDB is specifically optimized for fast read performance and compact store sizes. Performances can be compared to in-memory data structures such as Java collections (e.g. HashMap, HashSet) or other key-values stores (e.g. LevelDB, RocksDB).
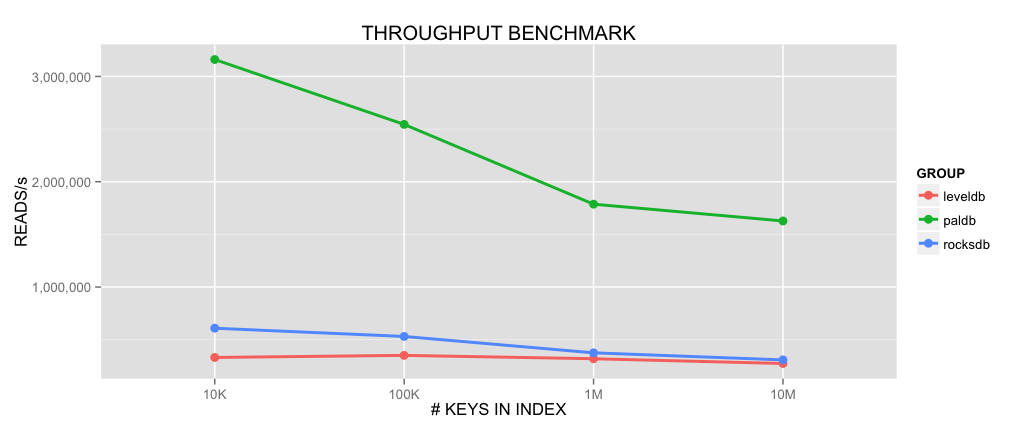
Current benchmark on a 3.1Ghz Macbook Pro with 10M integer keys index shows an average performance of ~1.6M reads/s for a memory usage 6X less than using a traditional HashSet. That is 5X faster throughput compared to LevelDB (1.8) or RocksDB (4.0).
Results of a throughput benchmark between PalDB, LevelDB and RocksDB (higher is better):
Memory usage benchmark between PalDB and a Java HashSet (lower is better):

Side data can be defined as the extra read-only data needed by a process to do its job. For instance, a list of stopwords used by a natural language processing algorithm is side data. Machine learning models used in machine translation, content classification or spam detection are also side data. When this side data becomes large it can rapidly be a bottleneck for applications depending on them. PalDB aims to fill this gap.
PalDB can replace the usage of in-memory data structures to store this side data with comparable query performances and by using an order of magnitude less memory. It also greatly simplifies the code needed to operate this side data as PalDB stores are single binary files, manipulated with a very simple API (see below for examples).
API documentation can be found here.
How to write a store
StoreWriter writer = PalDB.createWriter(new File("store.paldb"));
writer.put("foo", "bar");
writer.put(1213, new int[] {1, 2, 3});
writer.close();How to read a store
StoreReader reader = PalDB.createReader(new File("store.paldb"));
String val1 = reader.get("foo");
int[] val2 = reader.get(1213);
reader.close();How to iterate on a store
StoreReader reader = PalDB.createReader(new File("store.paldb"));
Iterable<Map.Entry<String, String>> iterable = reader.iterable();
for (Map.Entry<String, String> entry : iterable) {
String key = entry.getKey();
String value = entry.getValue();
}
reader.close();For Scala examples, see here and here.
PalDB is available on Maven Central, hence just add the following dependency:
<dependency>
<groupId>com.linkedin.paldb</groupId>
<artifactId>paldb</artifactId>
<version>1.2.0</version>
</dependency>Scala SBT
libraryDependencies += "com.linkedin.paldb" % "paldb" % "1.2.0"Can you open a store for writing subsequent times?
No, the final binary file is created when StoreWriter.close() is called.
Are duplicate keys allowed?
No, duplicate keys aren't allowed and an exception will be thrown.
Do keys have an order when iterating?
No, like a hashtable PalDB stores have no order.
PalDB requires Java 6+ and gradle. The target Java version is 6.
gradle buildPerformance tests are run separately from the build
gradle perfTestWe use the TestNG framework for our unit tests. You can run them via the gradle clean test command.
Coverage is run using JaCoCo. You can run a report via gradle jacocoTestReport. The report will be generated in paldb/build/reports/jacoco/test/html/.
Write parameters:
load.factor, index load factor (double) [default: 0.75]compression.enabled, enable compression (boolean) [default: false]Read parameters:
mmap.data.enabled, enable memory mapping for data (boolean) [default: true]mmap.segment.size, memory map segment size (bytes) [default: 1GB]cache.enabled, LRU cache enabled (boolean) [default: false]cache.bytes, cache limit (bytes) [default: Xmx - 100MB]cache.initial.capacity, cache initial capacity (int) [default: 1000]cache.load.factor, cache load factor (double) [default: 0.75]Configuration values are passed at init time. Example:
Configuration config = PalDB.newConfiguration();
config.set(Configuration.CACHE_ENABLED, "true");
StoreReader reader = PalDB.createReader(new File("store.paldb"), config);A few tips on how configuration can affect performance:
PalDB is primarily optimized for Java primitives and arrays but supports adding custom serializers so arbitrary Java classes can be supported.
Serializers can be defined by implementing the Serializer interface and its methods. Here's an example which supports the java.awt.Point class:
public class PointSerializer implements Serializer<Point> {
@Override
public Point read(DataInput input) {
return new Point(input.readInt(), input.readInt());
}
@Override
public void write(DataOutput output, Point point) {
output.writeInt(point.x);
output.writeInt(point.y);
}
@Override
public int getWeight(Point instance) {
return 8;
}
}The write method serializes the instance to the DataOutput. The read method deserializes from DataInput and creates new object instances. The getWeight method returns the estimated memory used by an instance in bytes. The latter is used by the cache to evaluate the amount of memory it's currently using.
Serializer implementation should be registered using the Configuration:
Configuration configuration = PalDB.newConfiguration();
configuration.registerSerializer(new PointSerializer());At LinkedIn, PalDB is used in analytics workflows and machine-learning applications.
Its usage is especially popular in Hadoop workflows because memory is rare yet critical to speed things up. In this context, PalDB often enables map-side operations (e.g. join) which wouldn't be possible with classic in-memory data structures (e.g Java collections). For instance, a set of 35M member ids would only use ~290M of memory with PalDB versus ~1.8GB with a traditional Java HashSet. Moreover, as PalDB's store files are single binary files it is easy to package and use with Hadoop's distributed cache mechanism.
Machine-learning applications often have complex binary model files created in the training phase and used in the scoring phase. These two phases always happen at different times and often in different environments. For instance, the training phase happens on Hadoop or Spark and the scoring phase in a real-time service. PalDB makes this process easier and more efficient by reducing the need of large CSV files loaded in memory.
Any helpful feedback is more than welcome. This includes feature requests, bug reports, pull requests, constructive feedback, etc.
PalDB © 2015 LinkedIn Corp. Licensed under the terms of the Apache License, Version 2.0.